
LOOPE - Lingo Object Oriented Programming Environment by Irv Kalb
Section 1 - Parent Scripts and Objects
Sometimes when we see a new technology, we are interested not only in how to use it (the external view), but also how it works (the internal view). This chapter is all about how objects are implemented. If this does not interest you, feel free to skip this chapter. However, I believe that knowing what's happening "under the hood", or at least developing a solid "mental model" of how it works, can help you gain a better understanding of using objects and object oriented programming.
If you think of Director as an object, then the Lingo language is Director's API (Application Programming Interface). You write code in Lingo but the underlying code and properties of Director are hidden from you. Just as in one of the fundamental elements of OOP, Macromedia can re-code the internals of Director without affecting your code. It seems that each release of Director brings with it an increase in the execution speed of Lingo code without any Lingo programmer having to change a single line of his or her code. To continue with this analogy, we (the users of Director) are not allowed to look at the source code of Director to see how it works internally. However, we can make guesses. Here I present my mental model of how basic OOP is implemented inside Director. (Some of what I present here was confirmed in a conversation with John Thompson, the "father" of Lingo.)
A compiler is a special program that takes code that you write in a higher-level language and translates it into code that the computer understands. Programmers write code in C or Pascal or Fortran, then run the appropriate compiler to translate the code in that language into machine code for a specific computer. Inside Director, Lingo also has what Macromedia calls a compiler. It doesn't actually translate Lingo into ones and zeroes like a pure compiler, instead it translates Lingo into Idealized Machine Layer (IML) code. The IML represents an ideal pseudo-computer, not a real existing one. This is actually a wonderful thing because it allows the same Lingo code to run on different platforms. Each IML operation such as add, subtract, etc. is assigned a byte code - a simple number. Then at run time, each byte code is translated into the exact instruction or instructions for the specific system on which the program is running.
When you program in most other high level languages, you have to write a lot of code to deal with managing memory. Fortunately for us Lingo developers, Director hides a great deal of the low level details of the underlying operating system and memory allocation from us. This is a very good thing. Lingo programmers rarely have to worry about how much memory is needed for something and never have to worry about what calls to different operating systems (Mac and Windows) are really being used. But if you want to dig in and try to really understand a little bit about memory, code generation, and addressing, I think you will find it very informative. It may seem like a roundabout explanation, but understanding how variables are managed will help to solidify an understanding of why OOP is a good thing.
Whenever you edit Lingo code in a script window and close the
script window, Director compiles that script into IML code. The IML code that
is "generated" by the Lingo compiler for each script is put in memory
somewhere. In this way, all compiled scripts are in memory and available to
run at all times. Here is an example of a simple handler in Lingo and what it
might look like after being compiled into IML. (If you have any familiarity
with assembly language, this should look very familiar.)
on AddTwoNumbers
v1, v2
returnValue = v1 + v2
return returnValue
end
The IML code that is generated from this handler might look something like this:
| Label: | Instruction: | Address: |
| AddTwoNumbers | LOAD | v1 |
| ADD | v2 | |
| STORE | returnValue |
The central processing unit (CPU) of most computers has a special place called an "accumulator" where math operations are performed. In the sequence of IML code above, the LOAD statement places the value of the variable v1 into the accumulator, then the value of the variable v2 is added to the accumulator, and finally, the result is stored into the variable returnValue.
At this point, I need you to make a leap of faith with me. For purposes of simplifying the following discussion, let's assume that the storage for every variable you use in Lingo takes up one memory address. In reality, it is a little more complicated than this. But making this agreement to suspend reality just a little by removing some confusing details about bits and bytes will make this discussion much easier to understand. Given this agreement that a single variable takes up one memory address, then it follows that a list of 'n' elements would take up 'n' memory addresses. Now let's say we execute the following line of Lingo code:
glNumbers = [30, 40, 50]
Then we want to reach into this list and get or set individual elements. How does the computer actually address these individual elements? To answer this, we need to have a way of describing memory. Computer Science students are often taught to think of memory as a linear array of memory cells. Each memory cell has an address (it's location, a simple integer starting at 1 or zero), and its contents (the current value). Here's how the list above might look in memory.
Because this may be the first time you have seen a memory diagram like this, let me explain it a little further. We have a Lingo variable called glNumbers that resides somewhere in memory. We really don't know where, and we really don't care where, and it really doesn't matter where - Lingo takes care of this for us. But because we're trying to explain what memory looks like, I've picked an address. Let's say that this variable lives at address 1000. Now we look at the contents of the memory address 1000 and find that it contains the value 1234. If this were a simple variable, Lingo would interpret this as the value 1234, and glNumbers would have that value. But because Lingo knows that this is a list, then the 1234 is interpreted as a pointer to, or the memory address of, where the real contents of the list glNumbers reside. That is, the contents of address 1234 is the value 30, this is the contents of glNumbers[1], at memory address 1235 is the contents of glNumbers[2], etc. If you change the contents of the list, for example assigning glNumbers = [1,2,3, 4], the address of glNumbers would stay the same (address 1000), but its contents, the place in memory where the list actually lives would probably change.
Most computers have a built-in way of addressing memory where you can generate the address of something you want by using what is called a "base" address and an "offset". To calculate an address, you add the value of the base and the value of the offset. For example, to get to the address of an element in a list, you use the base address of the list (the place in memory where the list starts and then add the offset (the item number you really want). However, because Lingo lists starting at an index of one, we have to subtract one to get the proper address. When using a base and an offset to generate an address to get to an element of a list, the compiler might generate an IML instruction like this:
| LOAD | ListBase, Offset |
This loads the value at the memory address that is calculated as the sum of the value in ListBase and the value of Offset. The following example should make this more clear. Imagine that we have a handler that looks like this:
global
glNumbers -- list of numbers
on SubtractTwoNumbers
glNumbers[1] = glNumbers[2]
- glNumbers[3]
end
Using the base plus offset style of addressing memory, the IML instructions generated for this SubtractTwoNumbers handler might looks like this.
| SubtractTwoNumbers | LOAD | glNumbers, 2 |
| SUB | glNumbers, 1 | |
| STORE | glNumbers, 0 |
This first line loads the element which is 2 memory addresses away from the base of the list glNumbers (this would be element number 3 in the list) into the accumulator. Then we subtract the value at the address which is 1 memory address away from the base of the list, (this is element number 2 in the list). Finally, we store the result into the memory address which is 0 memory locations away from the base of the address, (this is element number 1 in the list).
Understanding how memory is laid out and addressed will be very helpful in our understanding of how objects are implemented. From our discussions about objects so far, we know that a programmer creates an object dynamically. At author time, whenever you edit a script, Director compiles that script and puts a copy of the generated IML into memory - even if you have not created any objects from that script. At run time, when a program instantiates an object from a parent script, Director dynamically allocates memory for the property variables declared in the parent script. The amount of memory allocated when instantiating an object is very small - only enough memory to represent the properties.
Here is my understanding of the chain of events that happens when a program instantiates an object. A program executes a line of code such as:
oWhatever = new(script "SomeParentScriptName")
Director has a generalized "new" function that can take a number of different types of parameters (#bitmap, #flash, #cursor, #script, etc). Director's "new" function does different things depending on the type of the parameter passed in. Director's implementation of its "new" function must essentially have a big case statement which branches on the type of the parameter passed in. If Director's "new" function were written in Lingo, it would probably look something like this:
on new
someParam, param1, param2, param3, etc
case ilk(someparam)
of
#bitmap:
-- do bitmap stuff
#flash:
-- do flash stuff
#parentScript:
-- allocate memory
for this instance of the parent script
someMemoryAddress = rawNew(someParam)
-- call the "new"
method in the user's script
returnValue = new(someMemoryAddress,
param1, param2, param3, etc)
-- return the value
returned from the user's new method
return returnValue
#othertypes:
end case
end
When the parameter is a reference to a parent script (as we are trying to describe here), Director knows that the user wants to instantiate an object from that parent script. In this case, Director calls an internal routine (called "rawNew") to allocate a block of memory that is big enough for all of the script's properties. The function returns the address of the memory that has been allocated.
Director then calls the "new" method in the parent script, passing that memory address as the first parameter. Inside the parent script's "new" method, the first parameter is typically assigned to the "me" variable. Any other remaining parameters are assigned to the other variables. Then, any initialization code in the parent script's "new" handler runs. The last statement of a standard "new" method is typically, "return me". This returns the value of "me" to the Director "new" function. Finally, Director passes back that value to the instantiating line of code as the object reference.
|
As of Director 8, the memory allocation function ("rawNew") is available to be called directly from Lingo. You can make a call like this: oWhatever = rawNew(script "SomeParentScriptName") Director will allocate the memory needed for the properties of the parent script, and return that value to you, but it will not call the "new" method of that parent script. |
As an example, let's look again at the beginning of the bank account parent script from chapter 3:
-- BankAccount
script
property pPassword
property pBalance
on new
me,
password, initialBalance
pPassword = password
pBalance = initialBalance
return me
end
We instantiate a bank account object with a statement
such as:
oBankAccountA = new(script "BankAccount", "xyzzy", 400.00)
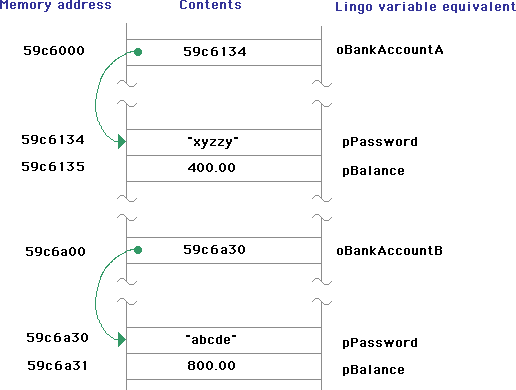
The parent script declares two properties. At run time, when we execute code to instantiate a bank account object, Director calls its internal function to allocate enough memory to represent those two property variables. The address of that allocated memory is then passed on to the BankAccount script's "new" method and is assigned to the parameter "me". The last line of code in this parent script's "new" handler is the standard: return me. Now it should be clearer as to why this is the case. When the "new" method returns, the address of the memory allocated for this object is stored into the variable oBankAccountA. oBankAccountA is an object reference variable whose value is the address of the memory allocated for a newly created bank account object. If we look at the value of oBankAccountA in the message window, we would get something like this:
put
oBankAccountA
-- <offspring "BankAccount" 2 59c6134>
Putting an object reference shows of three pieces of information. First, the object reference tells you that it is an offspring of the "BankAccount" parent script. The word offspring here is used here because of Director's concept of parent scripts and child objects. The object is considered an offspring of a parent script. In more general object oriented programming terms, the object is an instance of the parent script. Next, the number 2 here is the reference count. The reference count tells us how many variables are pointing to this object. In this case, oBankAccountA is one reference, and the "put" statement itself makes a second reference. Finally, there is the memory address of where the properties for this object have been allocated. In this case, the base memory address is 59c6134. The actual physical memory address for a given object is unimportant as no Director programmer deals with it as a number. However, the important concept here is that the object reference contains the base address of where to find properties for an instance of an object .
| In reality, the object reference only contains the address of the allocated memory. At that address are the properties and the reference count and the name of the parent script which was used to instantiate the object. The "put" command does some fancy footwork to format the information about the object reference the way it does. |
Consider what happens if we now instantiate a second bank account object.
oBankAccountB = new(script
"BankAccount", "abcde",
800.00)
put oBankAccountB
-- <offspring "BankAccount" 2 59c6a30>
Notice that the value of the object reference is almost identical, except that Director has allocated memory for this second bank account object at a different physical address (in this example, 59c6134 versus 59c6a30 earlier). So now we have created two bank account objects, (or, two instances of the bank account object), and we can see that the only difference in these two object references is that they point to two different addresses.
Back to addressing memory
To continue developing the mental model, you can think of properties declared in a parent script as being handled almost identically to elements in a list. For example, assume that you had the following declaration at the top of a parent script:
-- SomeThing parent script
property
pFirstProperty
property pSecondProperty
property pThirdProperty
When lingo compiles this parent script, it knows that it must allocate memory for three property variables. When you instantiate an object from the above parent script, the memory allocation for these variables will be done in a single chunk. That is, Director will allocate one block of 3 consecutive memory addresses to be the storage for these variables. That is, if you created an object like this:
oSomething = new(script "Something")
Then the memory allocated for this object would look like this:

In this case, pFirstProperty, being the first variable, will be zero memory locations away from the start of the block. Using the base and offset addressing scheme discussed earlier, the address of pFirstVariable will be oSomething, 0. Similarly, the address of pSecondVariable will be oSomething, 1, and the address of pThirdProperty will be oSomething, 2. As we will soon learn, the fact that these offsets are relative to some base address is vitally important to allowing multiple instances of objects.
So, here is what memory might look like after we have instantiated our two bank account objects:
Putting it all together
Let's pretend for a moment that that we can look at the IML code that the Director compiler would generate. Let's look at this simple method of the bank account object:
property
pPassword
property pBalance
-- ignore the new method for right now
on
mDeposit me, amountToDeposit
pBalance = pBalance + amountToDeposit
end
If you remember in the earlier discussion of the "me" variable, we said that "me" points to the current instance of the current object. To be even more specific, now we can see that "me" actually contains the base address of the current object. In effect, it points to the first property variable declared in the parent script. Therefore, using the base and offset addressing, the first property variable lives at address me, 0. The next property variable is at memory address me, 1, etc. The bank account parent script has two property variables; pPassword would be located at the address me, 0 and pBalance would be located at me, 1. So, the IML code for the mDeposit method might look something like this:
| mDeposit | LOAD | me, 1 | -- load the value of pBalance |
| ADD | amountToDeposit | -- add amountToDeposit | |
| STORE | me, 1 | -- store back into pBalance |
Now we can finally get to the heart of the matter. Let's see what happens when you call the mDeposit method of these two distinct objects that were instantiated from the same parent script:
oBankAccountA.mDeposit(200)
oBankAccountB.mDeposit(500)
With the above two lines of code, we are trying to deposit $200.00 into oBankAccountA and then $500.00 into oBankAccountB. Remember, there is only one copy of the bank account code compiled into IML and resident in memory, but there are two different addresses of data for the two instances of bank account object.

When the first line executes and calls the mDeposit method, the value of oBankAccountA is assigned to the variable "me", and 200 is assigned to amountToDeposit. Then the mDeposit code starts to execute. Using the base and offset approach to calculating an address, the value of pBalance of oBankAccountA (1 memory address away from the base address of the oBankAccountA object) is loaded into the accumulator. We then add the amountToDeposit. Finally, using the same address calculation, the new value is stored back into pBalance of oBankAccountA.
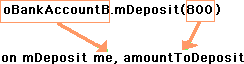
In the second call, the value of oBankAccountB is assigned to the variable "me", and 800 is assigned to amountToDeposit. When we make the second call, the exact same code executes. However, this time, the value assigned into the variable "me" is the base address of oBankAccountB, and the resulting calculation affects the pBalance of oBankAccountB.
So what does all this mean? It means that when using object oriented programming, you can have many instances of an object that share one set of code, but have independent sets of data (property variables). This works because every time you call a method of an object, you must give an object reference that specifies the instance of the object to which you are sending the message. The object reference is really just the address of where the first property of an object can be found.
There is another very important lesson to be learned here. We also should realize that instantiating a new object takes very little memory. When you instantiate a new object, Director only allocates the amount of memory needed to represent a copy of all the property variables.